1 Intro and Setup
Objectives
While most students will arrive having taken an introductory programming course and/or Summer python intensive workshop, it is important to start this class with some computer fundamentals and some setup and workflow preparation.
This chapter is meant to provide a resource for some basic computer skills and a guide to the workflow we expect you to follow when managing your code and data.
In this chapter you will:
- Learn the basics of a computer system.
- Create a GitHub account and practice using it for managing code and data artifacts.
- Practice using Google Colab notebooks for quick tasks and activities.
- Install
pythonlocally on your machine with Anaconda. - Practice opening and using
jupyternotebooks in Positron or VSCode or another IDE. - Install the
quartodocument rendering system. - Practice using
quartoto render nicely formatted html documents fromjupyternotebooks.
If you already feel comfortable with your own file organization system; you prefer GitLab over GitHub; or you prefer to use another python distribution and IDE (like VSCode), that is acceptable. Just know that we may be less able to help you and troubleshoot if you deviate from the recommended workflow.
For grading consistency, we will require that you submit quarto-rendered documents for all labs and projects.
1.1 Computer Basics
It is helpful when teaching a topic as technical as programming to ensure that everyone starts from the same basic foundational understanding and mental model of how things work. When teaching geology, for instance, the instructor should probably make sure that everyone understands that the earth is a round ball and not a flat plate – it will save everyone some time later.
We all use computers daily - we carry them around with us on our wrists, in our pockets, and in our backpacks. This is no guarantee, however, that we understand how they work or what makes them go.
1.1.1 Hardware
Here is a short 3-minute video on the basic hardware that makes up your computer. It is focused on desktops, but the same components (with the exception of the optical drive) are commonly found in cell phones, smart watches, and laptops.
When programming, it is usually helpful to understand the distinction between RAM and disk storage (hard drives). We also need to know at least a little bit about processors (so that we know when we’ve asked our processor to do too much). Most of the other details aren’t necessary (for now).
1.1.2 Operating Systems
Operating systems, such as Windows, MacOS, or Linux, are a sophisticated program that allows CPUs to keep track of multiple programs and tasks and execute them at the same time.
1.1.3 File Systems
Evidently, there has been a bit of generational shift as computers have evolved: the “file system” metaphor itself is outdated because no one uses physical files anymore. This article is an interesting discussion of the problem: it makes the argument that with modern search capabilities, most people use their computers as a laundry hamper instead of as a nice, organized filing cabinet.

Regardless of how you tend to organize your personal files, it is probably helpful to understand the basics of what is meant by a computer file system – a way to organize data stored on a hard drive. Since data is always stored as 0’s and 1’s, it’s important to have some way to figure out what type of data is stored in a specific location, and how to interpret it.
That’s not enough, though - we also need to know how computers remember the location of what is stored where. Specifically, we need to understand file paths.
When you write a program, you may have to reference external files - data stored in a .csv file, for instance, or a picture. Best practice is to create a file structure that contains everything you need to run your entire project in a single file folder (you can, and sometimes should, have sub-folders).
For now, it is enough to know how to find files using file paths, and how to refer to a file using a relative file path from your base folder. In this situation, your “base folder” is known as your working directory - the place your program thinks of as home.
1.2 Git and GitHub
One of the most important parts of a data scientist’s workflow is version tracking: the process of making sure that you have a record of the changes and updates you have made to your code.
1.2.1 Git
Git is a computer program that lives on your local computer. Once you designate a folder as a Git Repository, the program will automatically tracks changes to the files in side that folder.
1.2.2 GitHub
GitHub, and the less used alternate GitLab, are websites where Git Repositories can be stored online. This is useful for sharing your repository (“repo”) with others, for multiple people collaborating on the same repository, and for yourself to be able to access your files from anywhere.
1.2.3 Practice with Repos
If you are already familiar with how to use Git and GitHub, you can skip the rest of this section, which will walk us through some practice making and editing repositories.
First, watch this 15-minute video, which nicely illustrates the basics of version tracking:
Then, watch this 10-minute video, which introduces the idea of branches, and important habit for collaborating with others (or your future self!)
Working with Git and GitHub can be made a lot easier by helper tools and apps. We recommend GitHub Desktop for your committing and pushing.
1.2.4 Summary
For our purposes, it will be sufficient for you to learn to:
commit your work frequently as you make progress; about as often as you might save a document
push your work every time you step away from your project
branch your repo when you want to try something and you aren’t sure it will work.
It will probably take you some time to get used to a workflow that feels natural to you - that’s okay! As long as you are trying out version control, you’re doing great.

1.3 Anaconda and Jupyter
Now, let’s talk about getting python actually set up and running.

1.3.1 Anaconda
One downside of python is that it can sometimes be complicated to keep track of installs and updates.

Unless you already have a python environment setup that works for you, we will suggest that you use Anaconda, which bundles together an installation of the most recent python version as well as multiple tools for interacting with the code.
1.3.2 Jupyter
When you are writing ordinary text, you choose what type of document to use - Microsoft Word, Google Docs, LaTeX, etc.
Similarly, there are many types of files where you can write python code. By far the most common and popular is the jupyter notebook.
The advantage of a jupyter notebook is that ordinary text and “chunks” of code can be interspersed.
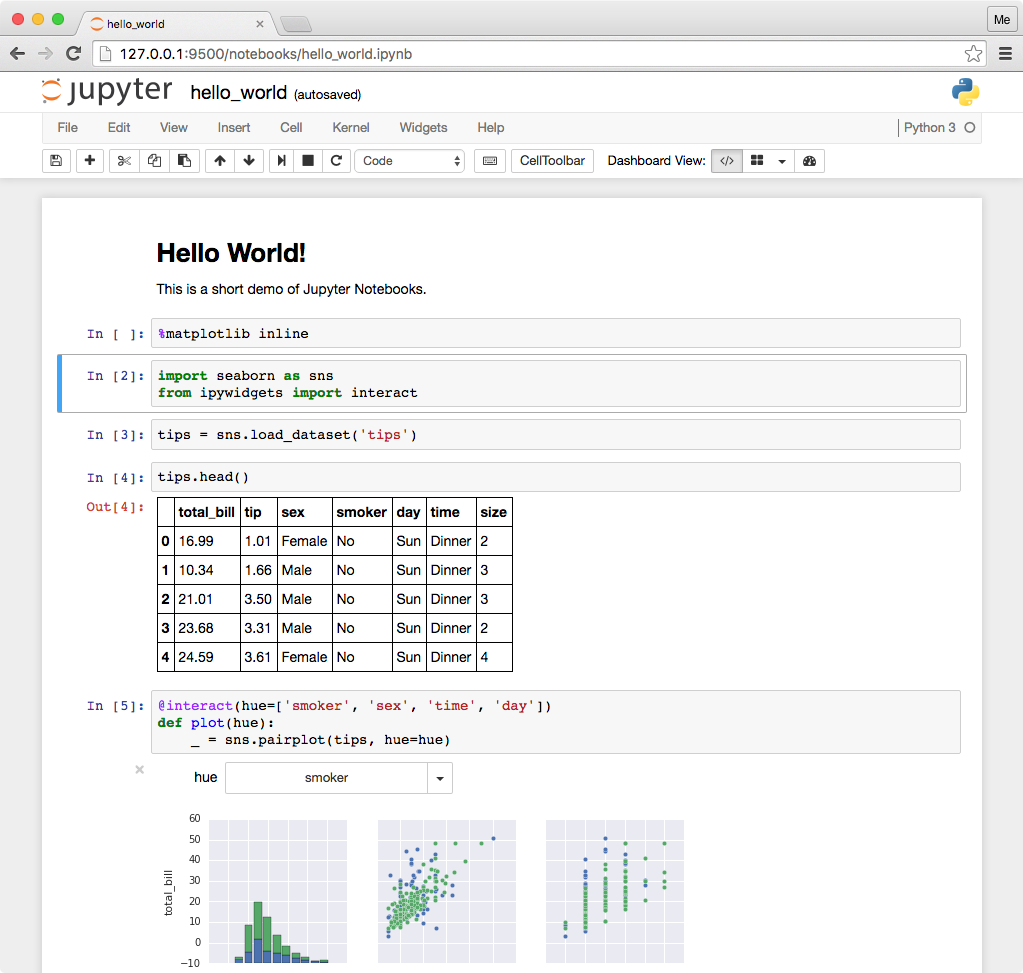
Jupyter notebooks have the file extension .ipynb for “i python notebook”.
1.3.2.1 Google Colab
One way you may have seen the Jupyter notebooks before is on Google’s free cloud service, Google Colab.
1.4 Quarto
Although jupyter and Colab are fantastic tools for data analysis, one major limitation is that the raw notebooks themselves are not the same as a final clear report.
To convert our interactive notebooks into professionally presented static documents, we will use a program called Quarto.
Once quarto is installed, converting a .ipynb file requires running only a single line in the Terminal:
quarto render /path/to/my_file.ipynbHowever, there are also many, many options to make the final rendered document look even more visually pleasing and professional. Have a look at the Quarto documentation if you want to play around with themes, fonts, layouts, and so on.
1.5 IDEs
Have you ever watched an old movie or TV show, and the “hacker” character is typing on a screen that looks like this?

Nobody in today’s programming world interacts with code as plain green text on a black screen. Instead, we take advantage of the tools available to make coding and data analysis more user-friendly. This usually means using an Integrated Developer Environment, or IDE: an application on your computer that provides a nice user interface for writing code.
In this class, you may use any IDE you prefer. You might be able to get by with only using Google Colab - but for many projects and assignments, this approach will be extremely inconvenient and require some frustrating steps in your workflow.
Instead, we would like to encourage you to use one of the following tools:
1.5.1 VS Code
We mention this first because it is currently the most commonly used IDE for programming. VSCode (“Visual Studio Code”) is released by Microsoft, and provides a clean interface, with multiple panels to help you organize multiple files.
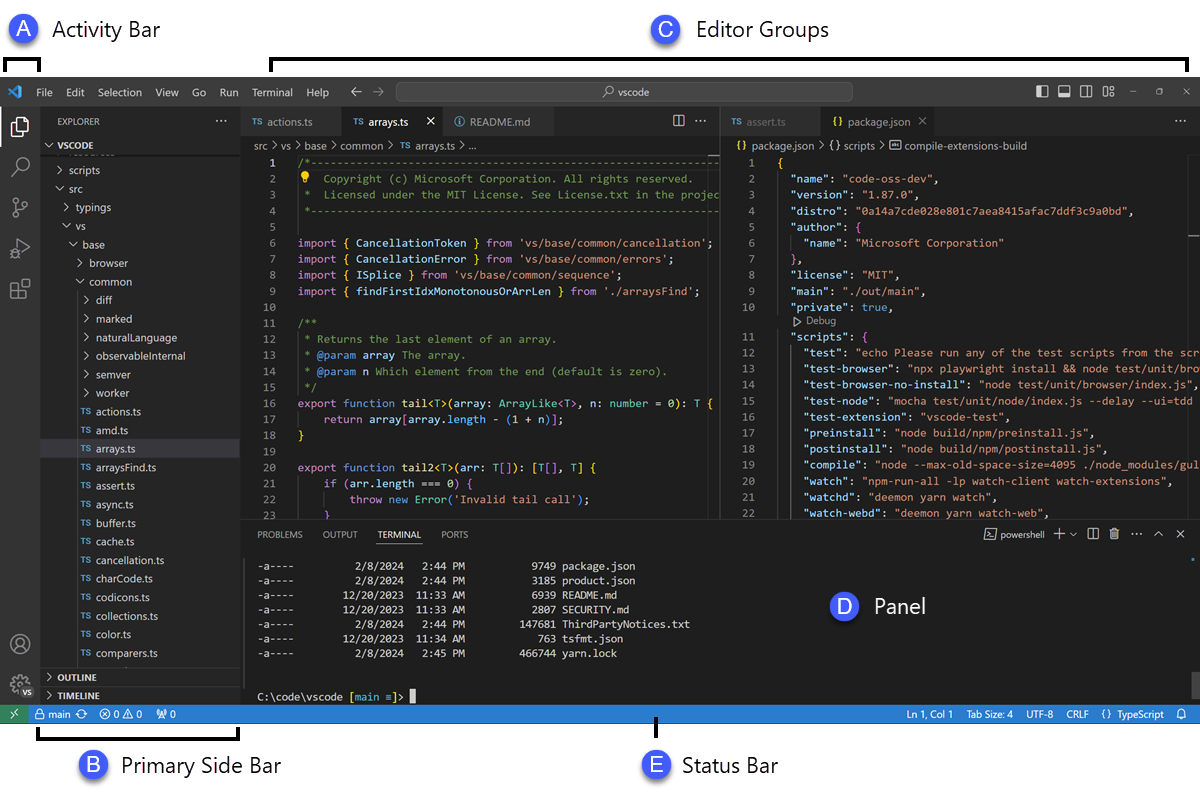
Pro: VSCode is very widely used; if you get comfortable in it now, you may be well prepared to work on teams that use it in the future.
Con: VSCode is more targeted at software development than data science. It lacks several data-specific conveniences that other IDEs implement, such as the ability to explore a loaded dataset in the IDE.
1.5.2 Positron (our current recommendation)
Positron is a data science targeted IDE recently released by Posit, PBC. It is build on the original open-source structure used by VSCode, so it has many similarities.

Pro: Nearly all the great elements of VSCode, plus some extra conveniences for data analysis and multi-lingual coding.
Con: It is currently in Beta stages, so the workflow you get used to now could change in the future.
Important: If you are on a PC, you will need to enable the Quarto Extension in Positron for it to work.
1.5.3 RStudio
For R users, there has historically only been one IDE worth using: RStudio. RStudio does support python and jupyter - so it is certainly a viable option for this class. However, there can be some frustrations in getting RStudio to recognize the correct installations of python and its packages. If you are already very familiar with RStudio, it might be worth working through the initial install challenges so you can stick with your comfort zone.
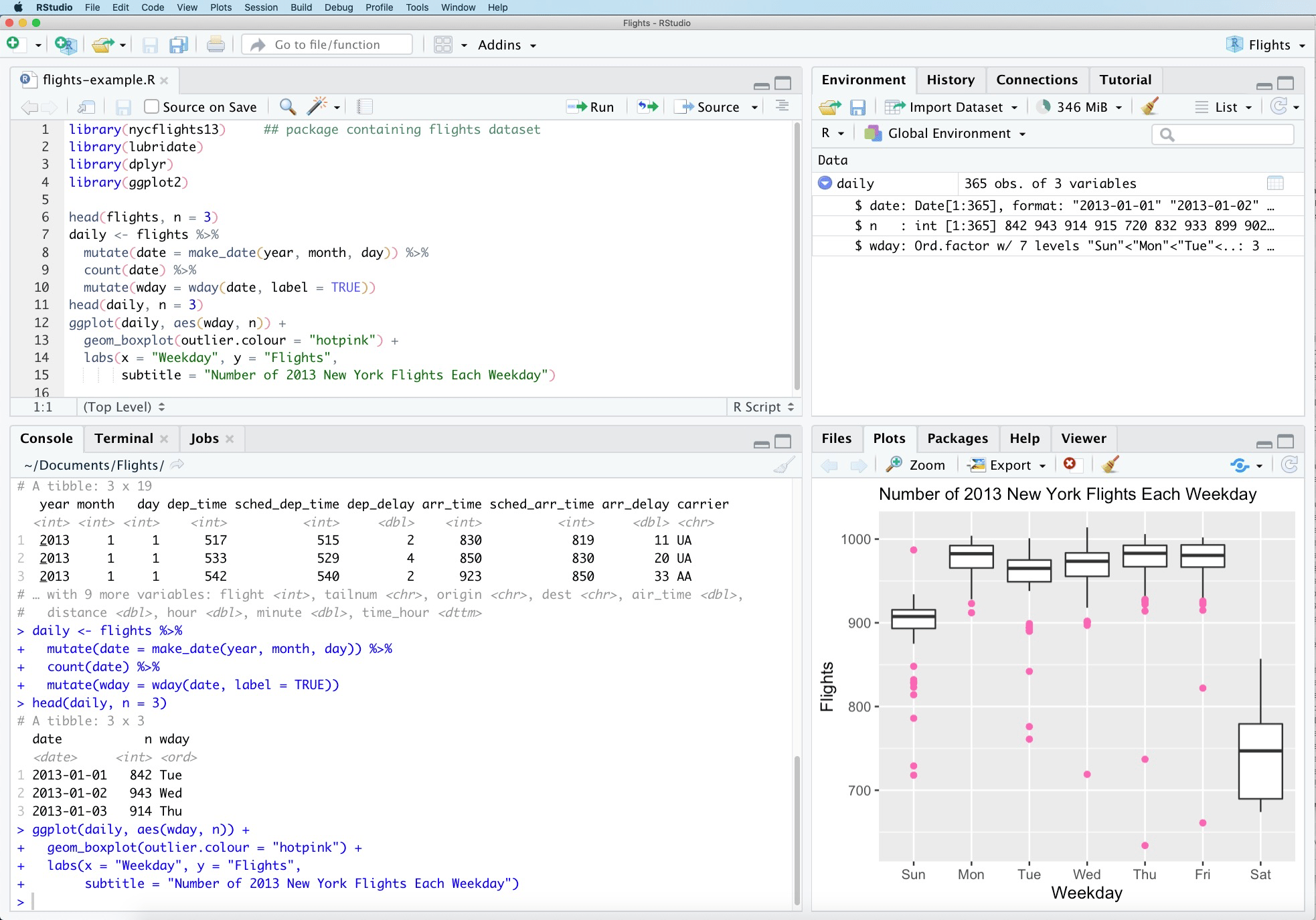
Pros: A very optimized data science IDE that is particularly great for R and for Quarto.
Cons: Can be a bit frustrating to use with python; most python users prefer VSCode or Positron.
1.5.4 Jupyter
Technically speaking, jupyter does provide its own built-in IDE, which is essentially a plain jupyter notebook much like Google Colab.
You can access this through Anaconda.
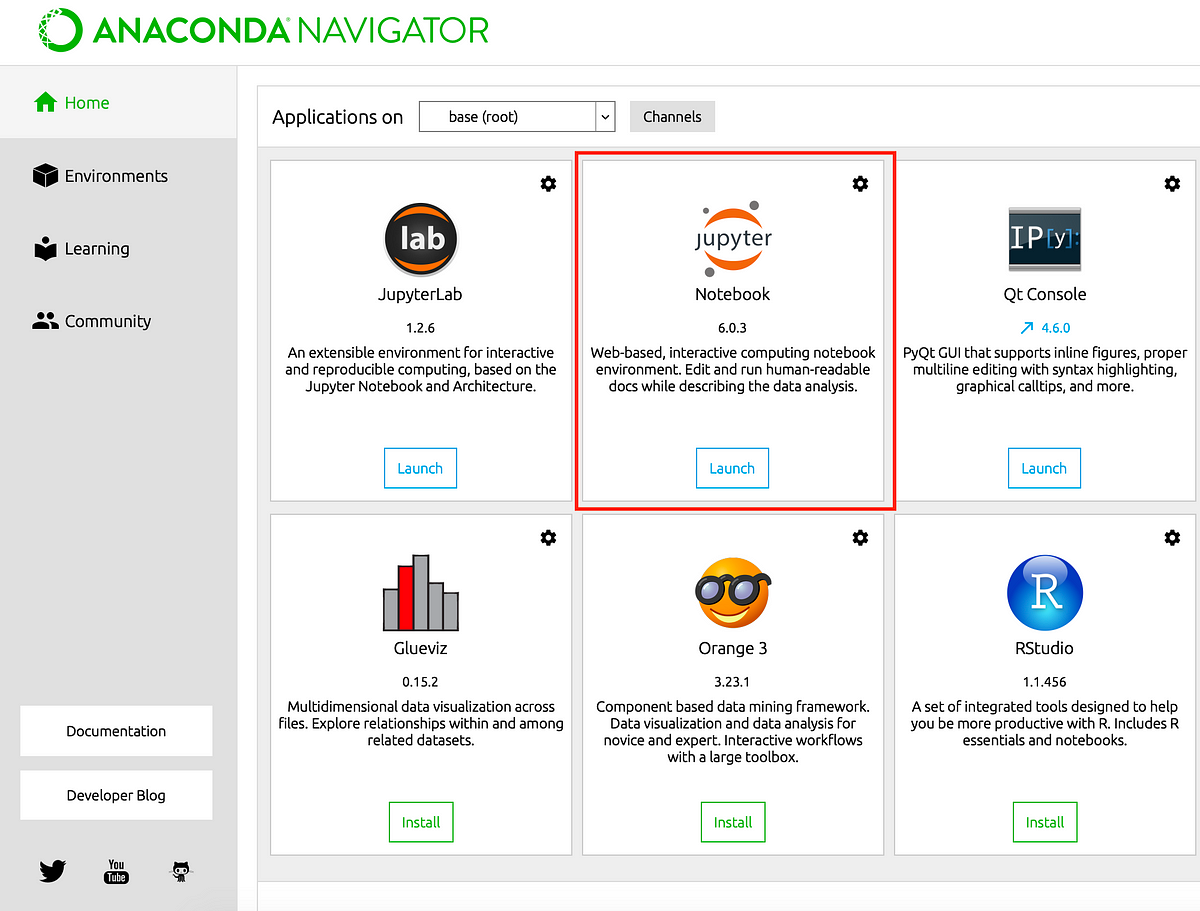
We do not recommend this workflow; as it can get rather tedious to click through your folder structure and open individual documents, and none of the conveniences of an IDE are available.
1.5.4.1 Try it!
1.6 The new world of GenAI
Every now and then, a technological advance comes along that changes the world very suddenly. These moments are exciting, but also particularly challenging for educators: how can we advise our students when this tool is as new to us as it is to them?
Our goal for this class is for you to leave with a good idea of how to use GenAI tools responsibly and effectively. We want to think carefully about the ethical concerns with AI, but we also want to find ways that AI can make our data analysis process stronger, better, and easier.
While we have put a lot of effort into the activities and resources in this textbook, we also hope that you will view this learning process as a collaborative one between us and you. As you encounter new ideas, new tools, or new challenges, we hope you will not hesitate to share those with us and your classmates.
1.6.1 A brief history
Although it is far from the first Generative AI Model, GenAI exploded on the public scene with the introduction of ChatGPT on November 30, 2022. ChatGPT stands for generative pre-trained transformer, and it is released by OpenAI, an organization founded in 2015. (The “original” ChatGPT - the first one released to the public - is actually version 3.5.)
Since then, advances have been rapid. Several similar GenAI tools have popped up, including: Google’s Gemini, Anthropic’s Claude, Meta’s Llama, and Baidu’s Ernie. As of writing this in 2024, the most cutting-edge model is Chat-GPT 4o, the 3rd major public release from OpenAI.
These tools are often referred to as LLMs (Large Language Models), since they focus on generating human-like text; unlike other generative AI models that might produce images, sounds, numeric output, etc.
1.6.2 The birth of an LLM
The principle behind an LLM is not complicated, and not different than the predictive models we will study in this class.
Gather some training data, which provides examples of possible inputs and the corresponding correct outputs.
Specify a model equation. For example, in simple linear regression, the equation is output = slope times input plus intercept, often written as y = mx + b
Use the training data to train the model; i.e. to calculate the parameters. In linear regression, the two parameters are m and b, the slope and intercept.
When new data becomes available, where we only have the input values, plug these values into the trained model equation to obtain predicted output values.
So, what makes an LLM so extremely different from a simple linear regression? Three elements:
Quantity of training data. You might train a simple linear regression on a dataset with 100 rows and two columns. The dataset used to train ChatGPT 3.5 is unimaginably large: essentially, the entirely of all text written by humans available on the internet between 2016 and 2019, equating to roughly 500 billion rows of data.
Complexity of the model. Note that a complex model is not the same as a complicated one: complexity means that we have many, many parameters. The model equations themselves remain relatively simple. A simple linear regression has two parameters: slope and intercept. The original ChatGPT 3.5, and most of the other models mentioned, have around 100-200 billion parameters. ChatGPT 4.0 is estimated to have 1.76 trillion parameters.
Generative vs predictive. A classic predictive model will typically input a single number \(x\) and output a single predicted number \(y\). A generative model takes human text and input, and instead outputs a probability distribution giving the probability of every possible word that could be a response to the human prompt. The LLM then samples from that distribution, randomly choosing a word, and then the next word, and then the next. This means that giving an LLM identical input won’t result in identical output.
1.6.2.1 Cost and resources
If the procedure and equations for an LLM are not overly complicated, why did they not come on the scene until 2022?
The answer is quite simple: training an LLM, with such enormous data and complexity, requires an absolutely unbelievable amount of computing resources.
The cost of training ChatGPT-3.5 was approximately $5 million. It took several months to train, on a massive supercomputer running constantly the whole time. The amount of computation power used can be thought of like this: If you were to buy a top-of-the line personal laptop, for about $4000, you would need to run it continuously for almost 700 years to train ChatGPT-3.5. (source)
The size of ChatGPT-4 is not public; however, it is estimated to have cost $100 million.
All this is to say: to create an LLM on the scale of those popular today, an organization must have the funding, resources, and time to…
… gather or purchase an inconceivable amount of data …
… build a networked supercomputer …
… run the supercomputer continuously for months …
… before the LLM can be used for anything at all!
1.6.2.2 The prediction step
All of this is what is needed to train the model. What about the prediction step? (Sometimes called inference in the AI world; although this term has a different meaning in statisics.)
Well, once the model parameters are computed, putting in input and getting back output is a much lower computation load. But it is not totally free - and as you can imaging, there are a huge number of prompts and responses to the models every day.
The cost of a typical prompt-and-response to ChatGPT 3.5 is about $0.0025, i.e., a quarter of a penny. For ChatGPT 4, it is around 9 cents. For this reason, at present users must pay for access to ChatGPT 4 but not 3.5. (source)
1.6.2.3 Environmental concerns
Another important consideration of the ongoing costs of GenAI is the use of earth’s resources.
The training and ongoing use of the model requires a supercomputer, housed in a large warehouse. These are located near water sources, both for the hydroelectric power, and to use water for cooling; leading to some concerns about the quantity of fresh water being used.
Perhaps more prominently, the supercomputers of course use massive amounts of electricity, producing a carbon footprint of C02 emissions from the generation process. The carbon footprint from training ChatGPT-3.5 is the same as driving about 120 vehicles for a year. This is, arguably, not a massively impactful amount in the context of human life - but many have concerns about this footprint scaling up rapidly, as we train more different and more complex models, and as the use of these trained models increases. (source)
1.6.3 Copyright and plagiarism issues
In the coming chapters, we will talk more about the responsibility of users of GenAI, like you and me, to make sure not to plagiarize. For now, though, we are focused on the creation of the LLMs.
Recall that LLMs are essentially trained on text scraped from the internet. Text produced by an LLM is not new - it is simply the model’s rearrangement of the words and letters that it learned from the training data. So - is this ethical and legal use of the training data gathered from online?
One extreme opinion is that no use of any GenAI tool is ethical unless all training data was given with explicit permission of the author.
If I copy text from a website and share it without attribution, that is plagiarism. If I copy text from three websites, combine it together, and share it without attribution, that is plagiarism. If a GenAI copies text from thousands of websites and combines it, perhaps that too is always plagiarism.
An opinion on the other extreme is that any data available in public is acceptable to use for training.
This philosophy holds that, essentially, all human writing is the result of our brains processing “training data” from all the text we have ever read, and rearranging the words in new ways. Why is an LLM any different?
The core question is: Is training a model a fair use of Intellectual Property? It is a question without a clear answer at present, and it is being hotly debated in philosophical and legal settings.
In this class, we will take the perspective that the current GenAI tools are, for better or for worse, legal and publicly available; and thus, we will make use of them in our work. At the same time, we will do our best to think critically about the ethical questions at stake, and to be responsible citizens of the new AI world.